PIFu/PIFuHD
PIFu/PIFuHD
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Target
从单张或多张RGB图像和图像中对应的人体mask信息,重建出图片或图片组中的人体三维模型和纹理信息。
PIFuHD没有纹理信息,但可以使用PIFu的方式同样生成
Pixel-Aligned Implicit Function
Implicit Function是用于表达物体表面的函数,如$f(\cdot)$,其中$f(x)=0$代表x在物体表面,$f(x)<0$代表$x$在物体内部,$f(x)>0$代表$x$在物体外部。
PIFu方法中提出的 PIFu则是讲2D图像中的Pixel也引入进来,所以叫做 Pixel-Aligned,其函数形式如下:
$f(F(x),z(X))=s,s \in R \ \ \ \ \ \ \ (1)$
$x=\pi(X)$为3D点X在2D图像上的投影,$z(X)$表示在此2D图片中对应的相机坐标系下的深度值。$F(x)=g(I(x))$表示2D图片在[公式]处的深度学习的特征向量,$g(\cdot)$是由一个全卷积网络组成。
PIFu,就是对于任意一个3D点$X_i$,先根据相机参数投影得到该点的2D点位置$x_i$以及在该相机下的深度$d_i$,同时找到该2D点位置的图像特征向量$v_{x_i}$, PIFu输出$f(v_{x_i},d_i)$表示该点是否在物体表面。
论文表示PIFu关键在于输入的Pixel-Aligned图像特征向量$v_{x_i}$,学习得到的$f(\cdot)$可以在重建的模型中很好地保留图片当中呈现的一些细节。同时PIFu这种连续性地本质可以用一种使用内存较少的方式重建任意拓扑结构的几何信息,并且公式(1)中$s$可以替换为如rgb等数据。
整体流程
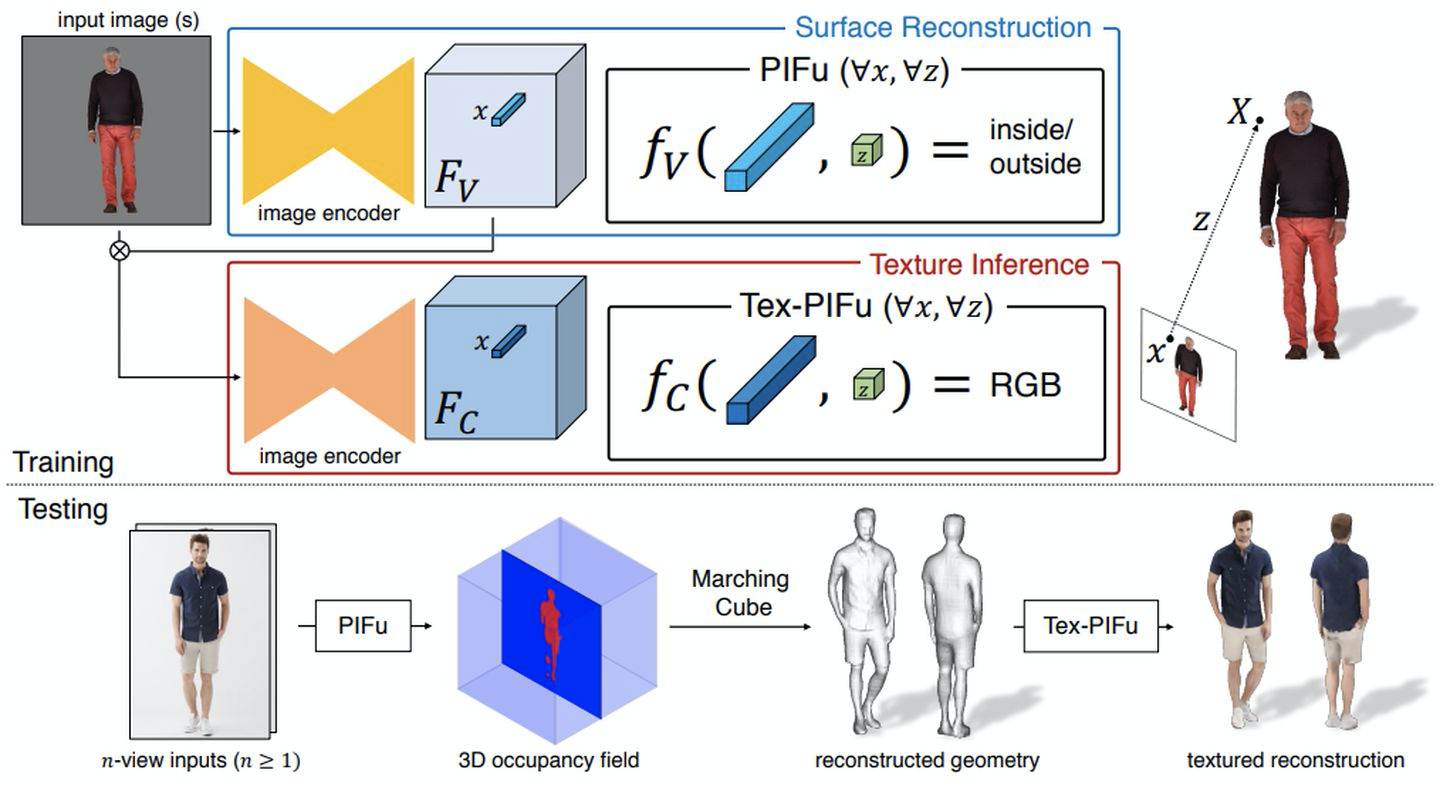
单视角重建
PIFu文章使用的表面GT Implicit Function:
$$
f_v^*(x)=\left{\begin{aligned}1&,\ if\ X\ is\ inside\ mesh\ surface\0&,\ otherwise\end{aligned}\right.
$$
$f_v^*>0.5$表示该点在物体内部;$f_v^*<0.5$表示该点在物体外部。这样的能将Implicit Function的值转变成了该3D点被物体占用的概率,值越靠近1表示被占有的概率越大,值越靠近0,则是空白区域的几率也越大,方便网络最后Sigmoid输出。
有的训练数据:m个对应的pair,(2D图像,3D模型)。
根据上图中PIFu 表面重建的流程: 对于每一个(2D图像,3D模型),2D图像会先输入到一个由全卷积组成的image encoder $g$,得到与原2D图大小一致的深度特征$F_V\in R^{h\times w\times c}$。对于3D模型,可以采样得到n个3D点${X_1,X_2,…,X_n}$, 同时可以知道其对应的Implicit Function的GT${f_v^*(X_1),f_v^*(X_2),…,f_v^*(X_n)}$
于是论文构建损失函数:
$$
L_v=\frac{1}{n}\sum_{i=1}^{n}{|f_v(F_V(x_i),z(X_i))-f_v^*(X_i)|}^2
$$
论文使用MLP去拟合上述的方程$f_v(\cdot)$。在梯度下降过程中,image encoder $g$和$f_v(\cdot)$是同时联合优化的(Surface Reconstruction)。image encoder $g$和$f_v(\cdot)$训练好之后,在推理阶段,输入就是一张图片和对应的相机参数,以及该图片中人体所处的一个大致范围(Bounding Box,$[x_{min},x_{max},y_{min},y_{max},z_{min},z_{max}]$)。对于Bounding Box,我们可以在三个维度上进行离散化,比如每个维度512,就可以得到$512\times512\times512$个点$X_i$,对所有的点输入到$f_v(\cdot)$函数中,那就可以得到3D Occupacy信息,然后跑一遍Marching Cube就可以得到物体的模型。
颜色重建
将公式(1)中的$s$改成$rgb$,来获取3D点对应的颜色预测。
损失函数为:
$$
L_c=\frac{1}{n}\sum_{i=1}^{n}{|f_c(F_C(x_i),z(X_i))-C(X_i)|}
$$
其中$C(X_i)$表示的是3D点$X_i$在2D图像中投影的颜色。同样的也可以采用和表面几何重建的方式,同时优化image encoder 和 implicit function $f_c(\cdot)$(Texture Inference)。文章中提出,是用这种方式这样会很容易过拟合,这是因为在这种情况下$f_c(\cdot)$既要预测表面顶点的颜色,又要去学习物体潜在的3D信息,这样它才可以推断不同pose和不同形状的人体的不可见部分(比如背面顶点)的颜色信息。于是文章提出了另外一种方式,就是基于上一步骤中的到用于重建的深度特征$F_V$。在这种情况下$f_c(\cdot)$只需要关注顶点的颜色,而不需要去关注潜在的3D信息,所以上面的损失函数变成:
$$
L_c=\frac{1}{n}\sum_{i=1}^{n}{|f_c(F_C(x_i^{‘},F_V),z(X_{i,z}^{‘}))-C(X_i)|}
$$
表面顶点的$X_i^{‘}=X_i+\epsilon \cdot N_i$,其中$\epsilon \sim N(0,d)$,添加了一个偏移量使得该点的周围都是该颜色,能够让网络更好的学习出相关的特征。
多视角重建
![]()
多视角下,PIFu变成$f(mean(\Phi_{view_1},\Phi_{view_2},…,\Phi_{view_n}))=s$,即每一个点的特征为所有视角下该点特征的平均。
PIFuHD
由于显卡内存的限制,PIFu的输入图片的大小为$512\times512$,输出的特征为$128\times128$,且使用的是HourGlass作为image encoder,该网络结果可以达到整张图片的感受野,并且多对中间阶段输出的监督可以得到比较鲁棒的3D重建结果,但是这样的网络结构也限制了该方法输入更大分辨率的输入图片,同时也不能得到更高维度的特征。
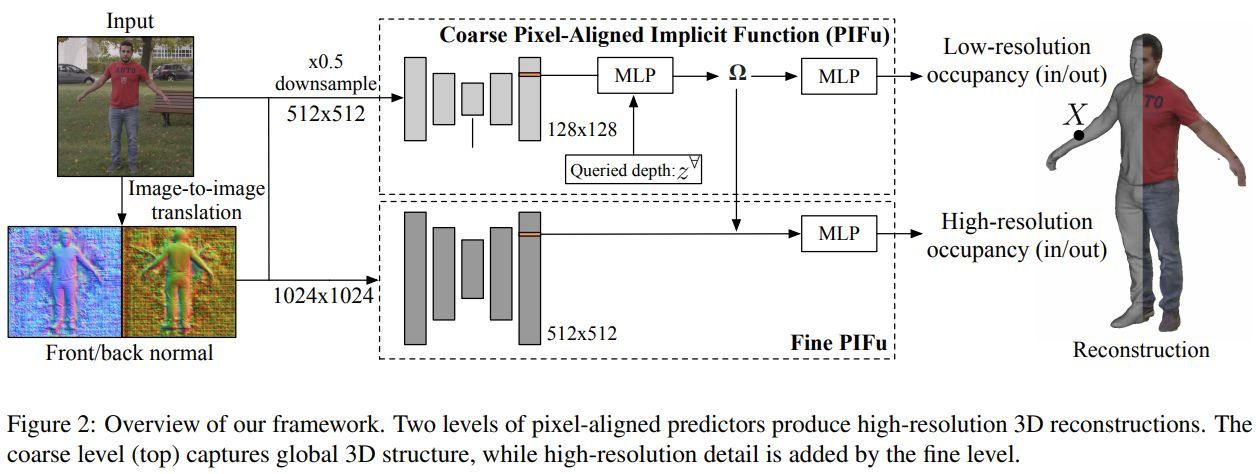
多层PIFu,输入是$1024\times1024$的图片$I_H$,输出是高精度的人体三维模型。
Coarse Level
与PIFu相同,输入的图片大小为$512\times512$,为原图经过下采样后得到的图片($I_L$),输出特征为$128\times128$。途中输入部分还添加了$512\times512$图片预测得到的正面、反面法相图$F_L,B_L$,此模块为:
$$
f^L(X)=g^L(\Phi^L(x_L,I_L,F_L,B_L,),Z)
$$其中$x_L\in R^2$是3D点$X$在$I_L$图片中2D的投影位置,$Z$为该相机视角下的深度,$\Phi^L$是提取图像特征的神经网络,$g^L$是MLP,从$X$的特征和投影深度$Z$判断该3D点是否在需要建模的人体内部
Fine Level
这个部分是的主干网络输入是原始的$1024\times1024$的图片$I_H$,输出$512\times512$大小的图像特征,得到大分辨率的特征图是为了能够得到三维模型上的精细细节。同样这个模块也输入了高分辨率的正面、反面法向图$F_H,B_H$:
$$
f^H(X)=g^H(\Phi^H(x_H,I_H,F_H,B_H,),\Omega(X))
$$其中$x_H\in R^2$是3D点$X$在$I_H$图片中2D的投影位置,且$x_H=2x_L$。
$\Phi^H$和$\Phi^L$有着相似的网络结构,主要的不同在于$\Phi^H$感受野没有覆盖这个图片,但是由于卷积网络的特性,可以通过滑动窗口的方式提取整张图像的特征。通过这种方式得到的特征就没有全局的信息,所以在$g^H$中,没有直接输入投影的深度$Z$,而是将coarse level中的全局特征$\Omega(X)$引入,以获取全局的特征信息。
由于Fine Level输入了Coarse Level的3D全局特征,所以经过Fine Level重建出来的结果不会差于Coarse Level单独的输出结果。如果网络设计能够很好利用高分辨率的图像信息,可以生成更好的三维模型。 另外,Fine Level不需要归一化可以让这一部分网络使用图片crop去进行训练,节省了显存。
Front-to-Back推理
在Coarse Level和Fine Level都是用了图片的正面、反面法相图,论文使用pix2pixHD网络将RGB图像预测出图片的正面和反面法相图。
在PIFuHD中使用了扩展BCE损失函数,即
![extbce][./2022/06/25/PIFu-PIFuHD/extbce.png]
在in/out采样数量不同的时候,会给数量较少的一方有更大的权重(类似focal loss)。
- pix2pix
pix2pix理解成image translate,在PIGFuHD中,利用一个Generator
Reference
论文解读 | PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
论文解读 | PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization