CUDA极简入门
CUDA极简入门
CUDA,Compute Unified Device Architecture
典型流程
- 分配host内存,并进行数据初始化
- 分配device内存,并从host将数据拷贝到device上
- 调用CUDA的核函数在device上完成指定的运算
- 将device上的运算结果拷贝到host上
- 释放device和host上分配的内存
CUDA数组、对象和资源的使用
一般使用cudaArray_t、cudaTextureObj_t和cudaSurfaceObj_t三种,并且常将同一个变量的三者(or less,但至少使用)形式进行绑定。cudaChannelFormatDesc和cudaCreateChannelDesc的使用为cudaArray_t、cudaTextureObj_t和cudaSurfaceObj_t进行格式创建描述,使用MallocCudaArray对相关Resource进行显存分配。同时,如果需要将GPU中的数据与CPU中的数据进行同步或交换,采用cudaMemcpy2DToArray和cudaMemcpy2DFromArray,完成GPU和CPU的数据同步。
Error定位
由于CUDA是跑在GPU上的程序,所有的变量分配也是存放在GPU中,因此不能够和CPU调试一样有详细的输出或堆栈调用。但我们在编写时总可能会遇到在某一些代码段出错的情况,但CUDA只会抛出异常,并不会定位到代码段,因此需要进行GPU代码模块的Error定位。
一般而言,我们在完成GPU相应的代码模块功能后,可以使用cudaGetLastError和cudaStreamSynchtonize来定位可能出现的CUDA Error。这两个指令可以追踪CUDA中遇到的Error,在程序中可以使用多个追踪。在CUDA模块运行出错后,程序会根据Error追踪指令提示到出错CUDA模块后的第一个cudaGetLastError,用此方式可以快速定位到编写的哪一个模块在最终运行时出现错误。
实际上,所有的CUDA API都会返回一个CUDA状态值,但我们一般不需要将所有的CUDA命令都进行出错判断。
From simple example
示例代码功能为利用CUDA实现灰度图片对应像素相加。(当然我还没跑过,虽然是我写的)
1 | |
Grid and Block
Grid和Block是CUDA编程中最重要的概念之一,以下图[Reference 1]为例,代表一个CUDA核函数kernel调用的Grid和Block图解。
blockDim.x是每一个Block内部的x方向的维度,图中5,即每行5个线程。blockDim.y是Block内部的y方向的维度,这里是3,即每列3个线程。blockIdx.x是Block在grid中x方向的位置,图中放大的Block是Grid中的2,即为Grid中x方向的第2个。blockIdx.y是Block在grid中y向的位置,图中放大的Block是Grid中的2,即为Grid中y方向的第2个。blockIdx中的Idx是表示index的缩写,而不是表示x方向的ID。
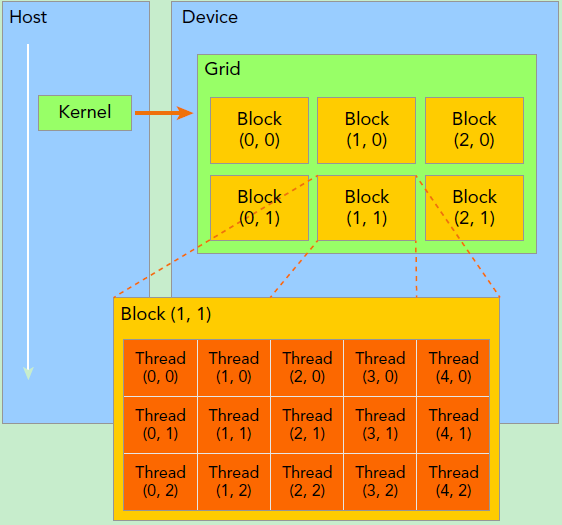
在CUDA kernel的使用时,需要传入<<<grid, block>>>参数。
CUDA C++ Basic
cudaCreateChannelDesc,创建cuda的通道描述符,在使用cudaMallocArray的时候需要将描述符一同传入进行cudaArray的内存申请。使用cudaChannelFormatDesc dev_a_desc = cudaCreateChannelDesc<uchar>();的使用方式生成通道描述符cudaArray_t, cudaSurfaceObject_t, cudaTextureObject_t为cuda中常用的三种数据类型格式,分别为数组类型、表面对象和纹理对象。表面对象和纹理对象通常会绑定到cuda数组- 若将
cudaArray_t, cudaSurfaceObject_t, cudaTextureObject_t利用CreateCudaTextureAndSurfaceObject的方式进行绑定,实际上cuda数组、表面对象和纹理对象都绑定在同一个显存区间中,仅是对象读写方式不同 cudaArray_t为cuda数组对象,是最重要的一个对象,在完成cuda数组对象的申请和分配后,才可以将相应的纹理对象、表面对象等绑定到数组对象中,并且使用cuda数组对象能更方便地与Host对象进行数据同步cudaTextureObject_t可读不可写,其读取速度可能比cudaSurfaceObject_t的速度快(未证实)。纹理对象会自动实现插值,即若取值为uv中没有恰好落在某个像素的时候,纹理对象会自动插值生成对应值cudaSurfaceObject_t可写,在对cudaArray_t需要进行更改的情况下一般都会将数组对象和表面对象进行绑定,并通过cuda kernel中surf2Dwrite函数将更新后的数值写入表面对象中,由于表面对象和数组对象是同一个绑定,因此cuda数组完成了更新
- 若将
cudaMallocArray是将数组对象在GPU中分配对应显存空间的函数,类似于CPU中分配内存的函数Malloc。但在对cuda对象进行显存分配的过程中,除了cuda数组对象、长宽和类型外,使用通道描述符来完成cuda数组对象类型的传入,如uchar, float4等cudaCreateTextureObject, cudaCreateSurfaceObject是将cuda数组对象与表面对象和纹理对象进行绑定的函数,将表面对象和纹理对象与cuda数组对象绑定后就能够使用相应对象完成后续操作cudaDestroyTextureObject, cudaDestroySurfaceObject是将表面对象和纹理对象进行销毁cudaFreeArray是将cuda数组对象申请的GPU显存进行释放cudaMemcpy2DToArray, cudaMemcpy2DFromArray分别是将Host对象拷贝到Device和Device对象拷贝到Hostsurf2Dwrite是将对应2D点的值写入到cudaSurfaceObject_t的表面对象中,cuda数组对象与表面对象绑定后并创建格式为cudaArraySurfaceLoadStore后可以使用此方式进行更改,同样的表面对象读取可以使用surf2Dread的方式完成cudaSafeCall,检查cuda函数返回值是否正确的判定宏
CUDA核函数
在CUDA C++的.cu文件中,函数前缀分为__host__, __global__, __device__三种
__host__为Host调用的函数,此类型函数无法被GPU调用,无法被__global__和__device__调用。若函数未表明前缀,默认为此前缀类型__global__前缀代表此函数为核函数,可以在Host中调用,被Device执行,并且此函数可以调用__device__前缀的函数,函数使用严格按照<<<grid, block>>>的方式进行,函数返回类型必须是void,不支持可变参数参数,不能成为类成员函数。用__global__定义的kernel是异步的,这意味着Host不会等待Kernel执行完就执行下一步__device__前缀表明此函数是在GPU中运行的,无法直接被CPU函数调用__host__和__device__可以同时使用
由于CUDA核函数中有不同的线程,因此需要传入grid和block参数给CUDA核函数进行使用。在CUDA核函数编写的时候,需要先计算出当前所在的线程idx,然后在参与计算。一个线程块上的线程是放在同一个流式多处理器(Streaming Multiprocessor,SM)上的,但是单个SM的资源有限,这导致线程块中的线程数是有限制的,现在的GPU线程块可支持的线程数可达1024个。当我们要知道一个线程在blcok中的全局ID,就必须还要知道block的组织结构,这是通过线程的内置变量blockDim来获得。它获取线程块各个维度的大小。对于一个2-dim的block$(D_x,D_y)$,线程$(x,y)$的ID值为$x+y\cdot D_x$,如果是3-dim的block$(D_x,D_y,D_z)$,线程$(x,y,z)$的ID值为$x+y\cdot D_x+z\cdot D_x\cdot D_y$。另外线程还有内置变量gridDim,用于获得网格块各个维度的大小。
如在2-dim的核函数中,一般有
$$
int \ \ pidx = blockIdx.x * blockDim.x + threadIdx.x \ int \ \ pidy = blockIdx.y * blockDim.y + threadIdx.y
$$
CUDA的内存模型,如下图所示。可以看到,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。
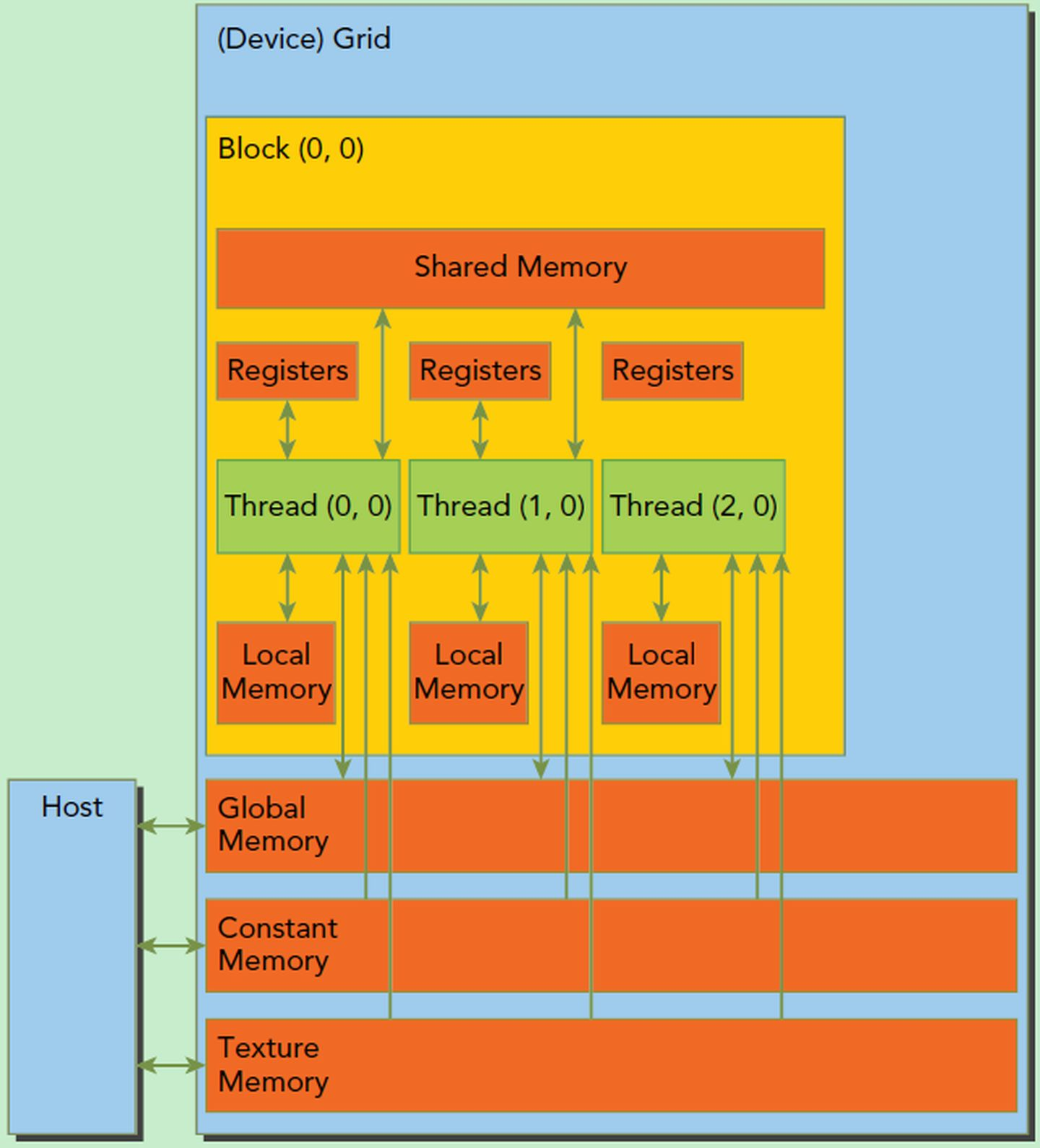
一个SM的基本执行单元是包含32个线程的线程束,因此block大小一般设置为32的倍数。